- My Data Dojo
- Posts
- Rerankers: A Complete Guide for Better Information Retrieval
Rerankers: A Complete Guide for Better Information Retrieval
Boosting Search with Smart Sorting
Sachin Nowal
August 06, 2025
If you’ve ever used a search bar, found what you needed at the very top, and thought “that was easy!”—you have ranking (and often, reranking) to thank. In today’s world of massive data and smart AI, rerankers have become key players behind the scenes, making sure the best answers show up first. Let’s break down rerankers in the most friendly, technical, and intuitive way possible.
What Is a Reranker?
Let’s say you search for “best pizza places near me.”
Behind the scenes, the search engine quickly grabs a bunch of possible places nearby. But not all of them are truly what you're looking for—some might be too far, have bad reviews, or aren’t even pizza places anymore.
That’s where rerankers come in.
A reranker is an AI-powered system that takes that rough list and does a second, smarter pass. It looks at more context: your location, reviews, popularity, freshness of data, even what kind of pizza people seem to love near you. Then it reorders the list, pushing the truly best options to the top. Now, when you check the first 2-3 results, they’re not just random guesses—they’re likely exactly what you wanted.
This two-step process—retrieve first, rerank later—is the secret behind smarter search experiences.
In technical terms, rerankers solve a key problem in information retrieval: initial search (called first-stage retrieval) is fast but shallow. It casts a wide net, grabbing a lot of potentially relevant items. But it often misses subtle cues—like a date filter (“after 2018”), a specific subtopic, or how well the document matches your real intent.
By adding a reranking step, systems can apply deeper understanding, often using large language models or neural networks, to sift through the rough list and refine the order. This boosts both precision and user satisfaction, without making the system unbearably slow.
So whether you’re searching for pizza, papers, or products, rerankers are what make sure the best stuff actually shows up at the top.
The Core Problem Rerankers Solve
Traditional one-stage retrieval systems, while fast and scalable, often struggle with several key challenges:
Initial Relevance but Poor Ranking: Systems might retrieve relevant documents but fail to rank them according to their true relevance to the query
Reducing Noise in Retrieved Results: First-stage retrieval can introduce documents that are somewhat relevant but not entirely aligned with user intent
Handling Complex Queries: Nuanced queries involving multiple facets require deeper understanding than simple keyword matching or basic similarity measures can provide
How Rerankers Work

The reranking process operates through a carefully orchestrated pipeline that maximizes both efficiency and effectiveness:
The Two-Stage Retrieval Process
Stage 1: Initial Retrieval
A fast retrieval system (such as vector similarity search, BM25, or TF-IDF) quickly identifies a broad set of candidate documents
This stage prioritizes speed and recall, ensuring potentially relevant documents aren't missed
Typically retrieves 20-100 candidate documents from a large corpus
Stage 2: Reranking
A more sophisticated model evaluates each query-document pair individually
Applies deeper semantic analysis and contextual understanding
Reorders candidates based on refined relevance scores
Returns the top-k most relevant results (usually 3-10 documents)
Technical Architecture
The smartest rerankers often use something called a cross-encoder—a type of deep learning model that looks at both the query and the document together. This helps it better understand if a result truly matches what you're looking for.
Cross-Encoder (More Accurate)
It takes the search query and a document, combines them, and feeds them into a model like a transformer.
The model compares words across both the query and document at the same time, understanding the full context.
It then gives a relevance score—basically, “how well does this document answer your question?”
This deeper comparison makes it much better at ranking results accurately, especially when details matter.
Bi-Encoder (Faster, but Less Accurate)
In contrast, bi-encoders treat the query and document separately.
They turn each one into a vector (a kind of numerical summary), and then compare them using math like cosine similarity.
This is much faster and good for grabbing a large set of candidates, but it’s not as good at understanding fine details.
Types of Rerankers
Modern reranking systems encompass several distinct approaches, each with unique strengths and optimal use cases:
🔢 Score-Based Rerankers
Weighted Rerankers
Combine results from different search methods (like keyword search and vector search).
You assign weights, like 70% from vector scores and 30% from keyword scores, to get a final ranking.
RRF (Reciprocal Rank Fusion)
A smart way to merge rankings from different systems without worrying about score differences.
Example: If a result ranks 2nd in one method and 5th in another, the final score is
1/2 + 1/5 = 0.7.Simple and works surprisingly well.
🤖 Neural Rerankers – Using AI Models for Smarter Results
BERT-based Rerankers
Use pre-trained language models (like BERT) to better understand the meaning of your query and the documents.
Great for catching subtle meanings that keyword matching misses.
LLM Rerankers (like GPT-style models)
These use large language models to do deep, intelligent reranking.
Super powerful for tricky or complex queries—but they need more compute power.
ColBERT and Multi-Vector Models
Try to find a middle ground: faster than full LLMs, smarter than simple models.
They break documents into parts and process them more efficiently, while still keeping some context.
TL;DR:
Score-based = combine results from different sources (fast + flexible).
Neural rerankers = smarter models that deeply understand language.
LLMs = most powerful, but slowest.
ColBERT-like models = balance between speed and intelligence.
When Should I Use a Reranker?
Great for:
Tricky questions where details matter.
When you care A LOT about showing the best answer (think medical, legal, or customer support apps).
When you’re okay with a little extra wait for much better results.
Not needed for:
Simple questions (“weather in Paris”) where plain search works fine.
Super-fast, real-time needs.
How Do You Know a Reranker Is Actually Better?
Radar chart comparing performance of different reranking methods across evaluation metrics like NDCG, recall, precision, MRR, MAP, and Hits@K
Metrics! Common ones are MRR (finds the first right answer quickly), NDCG (rewards ranking the best stuff at the top), Accuracy@K (“Did the top 3 have a good answer?”), etc.
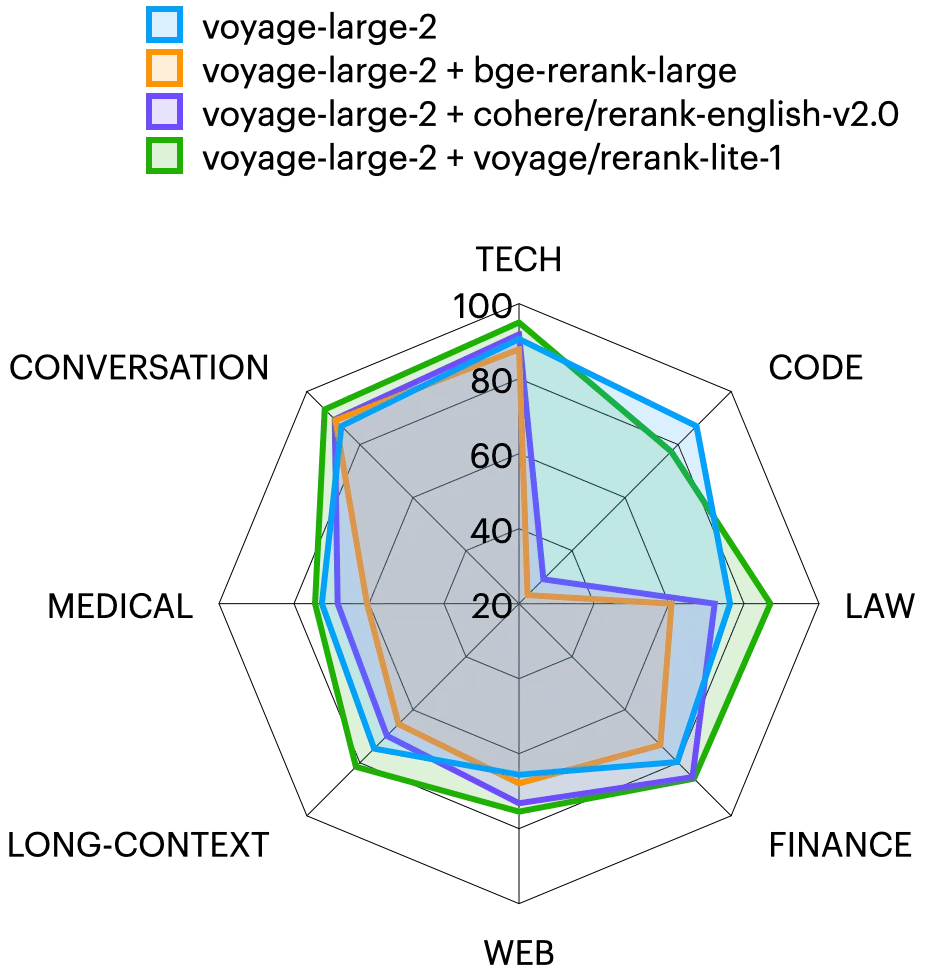
Conclusion
Rerankers represent a fundamental shift in how we approach information retrieval, moving beyond simple similarity matching to sophisticated relevance analysis. By implementing a two-stage retrieval process, organizations can significantly improve the accuracy and user satisfaction of their search systems while maintaining computational efficiency.
The choice of reranking approach should align with specific application requirements, balancing accuracy needs against computational constraints. As the field continues to evolve, we can expect even more sophisticated reranking methods that better understand user intent, handle multimodal content, and provide more granular control over retrieval behavior.
For organizations looking to enhance their information retrieval systems, rerankers offer a proven path to improved performance with relatively straightforward implementation. The key lies in careful evaluation of requirements, thorough testing of different approaches, and continuous monitoring of performance in production environments.
Happy searching!