- My Data Dojo
- Posts
- Understanding Proximal Policy Optimization
Understanding Proximal Policy Optimization
The Algorithm Powering ChatGPT and Beyond
Sachin Nowal
August 04, 2025
In the rapidly evolving landscape of artificial intelligence, one algorithm has quietly become the backbone of some of the most impressive breakthroughs we've witnessed—from ChatGPT's human-like conversations to robots learning complex manipulation tasks. Proximal Policy Optimization (PPO) represents a masterful balance between theoretical elegance and practical effectiveness, solving one of reinforcement learning's most persistent challenges: how to improve an AI agent's behavior without catastrophically destroying what it has already learned.
The Problem PPO Solves
Imagine teaching a student who has a peculiar learning disability: every time you give them a new lesson, there's a risk they might forget everything they've learned before. This is precisely the challenge that plagued early reinforcement learning algorithms. Traditional policy gradient methods, while theoretically sound, suffered from a critical instability—they were prone to taking policy updates so large that an agent could go from performing well to completely failing in a single training step.
The core issue lies in the fundamental tension between exploration and exploitation in reinforcement learning. An agent needs to explore new strategies to improve its performance, but it also needs to avoid straying too far from policies that are already working reasonably well. This balance becomes particularly crucial in high-stakes applications like autonomous driving or medical diagnosis, where catastrophic policy failures are unacceptable.
Trust Region Policy Optimization (TRPO) was an early attempt to address this problem by constraining policy updates within a "trust region"—a mathematically defined safe zone where the policy could change without risking performance collapse. While TRPO achieved impressive theoretical guarantees and practical results, it came with significant computational overhead, requiring complex second-order optimization methods and Hessian matrix computations that made it challenging to implement and scale.

Comparison of PPO vs TRPO across key performance dimensions
PPO emerged as an elegant solution that captures the essential benefits of TRPO while dramatically simplifying the implementation and reducing computational requirements. Rather than solving complex constrained optimization problems, PPO uses a remarkably simple clipping mechanism to prevent destructive policy updates, making it both more practical and more widely applicable.
The Mechanics of PPO: Clipping for Stability
The innovation of PPO lies in its clipped surrogate objective function, which provides a pessimistic lower bound on policy performance improvements. The algorithm operates on a fundamental insight: instead of explicitly constraining how much a policy can change (as TRPO does), we can clip the objective function to remove incentives for harmful updates.
The mathematical heart of PPO is the clipped surrogate objective:
LCLIP(θ)=Et[min(rt(θ)At,clip(rt(θ),1−ϵ,1+ϵ)At)]LCLIP(θ)=Et[min(rt(θ)At,clip(rt(θ),1−ϵ,1+ϵ)At)]
Where rt(θ)=πθ(at∣st)πθold(at∣st)rt(θ)=πθold(at∣st)πθ(at∣st) represents the probability ratio between the new and old policies, and AtAt is the advantage estimate.
This deceptively simple formula encodes profound algorithmic wisdom. The ratio rt(θ)rt(θ) measures how much more or less likely an action is under the current policy compared to the old policy. When this ratio is close to 1, the policies are similar; when it deviates significantly, the policies have diverged.
The clipping function constrains this ratio to stay within the range [1−ϵ,1+ϵ][1−ϵ,1+ϵ], typically with ϵ=0.2ϵ=0.2. This means the new policy can make actions at most 20% more or less likely than the old policy. The minimum operation then selects the more conservative of the clipped and unclipped objectives, ensuring that the algorithm always takes the safer path.
This mechanism handles different scenarios elegantly. When an action is estimated to be good (positive advantage) and is becoming more likely under the new policy (ratio > 1), clipping prevents the algorithm from becoming overly confident and making the action too probable. Conversely, when an action is estimated to be bad (negative advantage) and is becoming less likely (ratio < 1), clipping prevents the algorithm from over-penalizing the action.
The Actor-Critic Architecture
PPO employs an actor-critic architecture where two neural networks collaborate to learn optimal policies. The actor network πθ(a∣s)πθ(a∣s) learns the policy—the mapping from states to action probabilities. The critic network Vϕ(s)Vϕ(s) learns the value function—an estimate of the expected future reward from each state.
The advantage function A(s,a)=Q(s,a)−V(s)A(s,a)=Q(s,a)−V(s) plays a crucial role by measuring how much better a specific action is compared to the average action in a given state. This subtraction serves a critical purpose: it centers the learning signal around zero, reducing variance in policy updates and helping the algorithm focus on the relative quality of actions rather than their absolute rewards.
The critic network provides this baseline by estimating V(s)V(s), while the actor network uses the advantage estimates to update its policy. This division of labor allows PPO to learn more efficiently than methods that must estimate action values directly.
PPO in Practice: From Games to Language Models
PPO's practical impact extends far beyond academic benchmarks. In robotics, PPO has enabled breakthroughs in autonomous navigation, manipulation, and control tasks. Research has demonstrated PPO's effectiveness in training robots for real-world applications, from warehouse automation to precision assembly tasks.
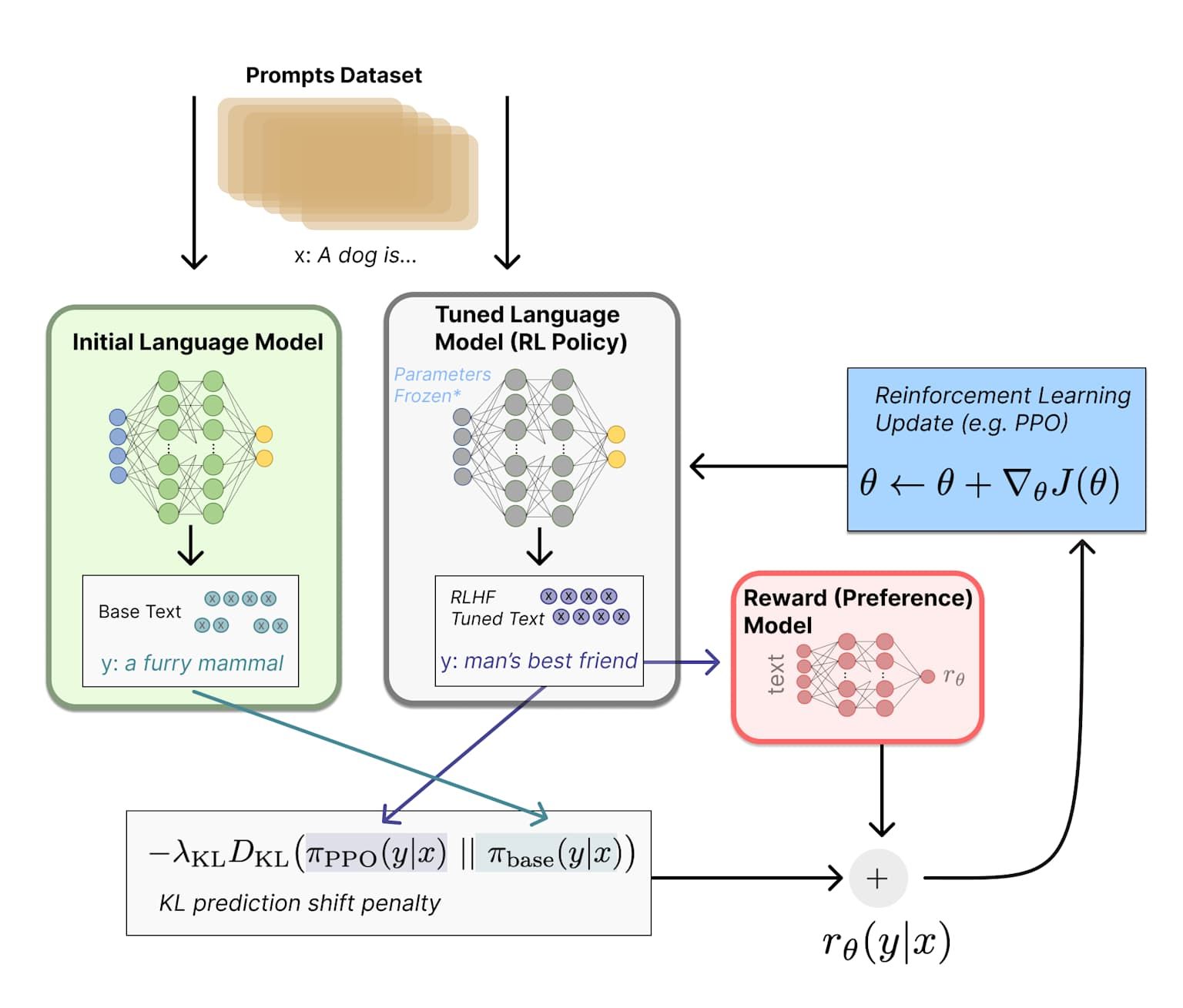
the RLHF process with PPO, showing the initial and tuned language models, reward modeling, and policy updates
Perhaps most notably, PPO serves as the optimization engine behind large language model alignment through Reinforcement Learning from Human Feedback (RLHF). OpenAI's InstructGPT and ChatGPT rely heavily on PPO to fine-tune language models according to human preferences. The process involves training a reward model on human preference data, then using PPO to optimize the language model's policy to maximize rewards while staying reasonably close to the original pre-trained model.
This application demonstrates PPO's versatility—while originally designed for traditional control tasks, it adapts remarkably well to the discrete token generation process of language models. The algorithm's stability properties prove particularly valuable in this context, where catastrophic policy failures could result in models generating harmful or nonsensical content.
In autonomous systems, PPO has shown promise for vehicle control, drone navigation, and traffic optimization. Its sample efficiency and stability make it particularly suitable for applications where gathering training data is expensive or risky.
Challenges and Limitations
Despite its successes, PPO faces several inherent limitations that researchers continue to address. Hyperparameter sensitivity remains a significant challenge—the algorithm's performance can vary dramatically based on choices like the clipping parameter ϵϵ, learning rate, and batch size. While ϵ=0.2ϵ=0.2 works well in many cases, finding optimal hyperparameters for specific domains often requires extensive experimentation.
Sample efficiency, while improved compared to earlier methods, still presents challenges in environments where data collection is expensive. PPO's on-policy nature means it cannot reuse old data as effectively as off-policy methods, potentially limiting its applicability in scenarios with limited interaction budgets.
The algorithm also struggles with sparse reward environments where meaningful feedback is rare. In such settings, PPO may require extensive exploration before discovering rewarding behaviors, making it less suitable than methods specifically designed for exploration.
Scalability presents another concern. While PPO is more computationally efficient than TRPO, training on high-dimensional observation spaces or complex environments still requires significant computational resources. This limitation can prevent deployment in resource-constrained settings.
Recent research has identified that PPO's clipping mechanism, while providing stability, can sometimes be overly conservative, preventing the algorithm from fully exploiting beneficial updates. This has led to the development of variants like Trust Region-Penalized PPO and other modifications that attempt to better balance stability and learning speed.
Looking Forward
As reinforcement learning continues to evolve, PPO remains a cornerstone algorithm, but researchers are actively developing improvements and alternatives. Recent work has explored combining PPO with diffusion models to improve sample efficiency, integrating it with evolutionary algorithms for better exploration, and developing variants that better handle multi-agent environments.
The rise of large language models has also spurred innovations in PPO's application to discrete action spaces, leading to methods like Reinforcement Learning from AI Feedback (RLAIF) and improved techniques for handling the massive scale of modern language models.
Understanding PPO provides crucial insights into the broader challenges of safe and stable learning in artificial intelligence. As we deploy AI systems in increasingly critical applications—from healthcare to autonomous vehicles—the principles embodied in PPO's design become ever more relevant. The algorithm's emphasis on controlled, stable updates while maintaining learning effectiveness offers a template for developing trustworthy AI systems.
The journey from vanilla policy gradients to PPO illustrates a fundamental truth in artificial intelligence: sometimes the most impactful innovations come not from complex mathematical breakthroughs, but from elegant solutions that make powerful techniques practical and reliable. PPO's success lies not just in its theoretical properties, but in its remarkable ability to work consistently across diverse domains, making advanced reinforcement learning accessible to practitioners worldwide.
As we continue to push the boundaries of what AI can achieve, PPO's legacy extends beyond any single application—it represents a philosophy of building AI systems that can learn and improve while maintaining the stability and reliability necessary for real-world deployment. In this balance between advancement and stability, PPO has found its place as one of the most influential algorithms of the modern AI era.