- My Data Dojo
- Posts
- How Synthetic Data Powers Expedia's Flight Price Forecasting
How Synthetic Data Powers Expedia's Flight Price Forecasting
Manufacturing Perfect Datasets for accurate flight price forecasting
Sachin Nowal
August 13, 2025
As data scientists and machine learning engineers, we often dream of perfect datasets. We imagine vast, clean, and perfectly structured tables, ready for our models to consume. But reality, as we know, is messy. In the world of flight price forecasting, this messiness manifests as a critical challenge: data sparsity. Even with millions of user searches, the data we collect is often incomplete for the granular task of predicting future prices.
At Expedia Group, the team faced this exact problem. How do you build a reliable price forecasting model when the very data you need has gaps? The answer is both elegant and pragmatic: if you don't have the data you need, you generate it yourself. This is the story of how synthetic search data became the cornerstone of their flight price forecasting models, a solution that brilliantly balances modeling needs with real-world engineering constraints.

The Core Problem: The Illusion of "Big Data"
On the surface, an online travel agency like Expedia seems to have an abundance of data. Millions of travelers search for flights every day, creating a massive firehose of organic search events. The intuition is that this data should be more than enough to train a forecasting model.
However, the devil is in the details of the forecasting task. To predict the price of a flight, you need a consistent time series. Specifically, for a given flight itinerary, you need to observe its price every single day leading up to the departure date. An itinerary, in this context, isn't just a route like New York (JFK) to Los Angeles (LAX). It's a highly specific tuple:
Itinerary=(origin, destination, trip_start_date, trip_length, search_date) The goal is to forecast how the price for a fixed (origin, destination, trip_start_date, trip_length) combination evolves as the search_date gets closer to the trip_start_date.
Now, consider the sheer combinatorial space. For a single route, there are hundreds of possible departure dates and dozens of trip lengths. The number of possible combinations is astronomical. While organic search traffic is high, it's also stochastic. On any given day, there's no guarantee that a user will search for the exact combination your model needs to track.
Even for a popular route like LAX-JFK, if we want to track the price for a flight departing on December 15th for a 7-day trip, it's entirely possible that on some days—say, October 20th and 21st—no one happens to perform that exact search. This creates holes in our time series data.
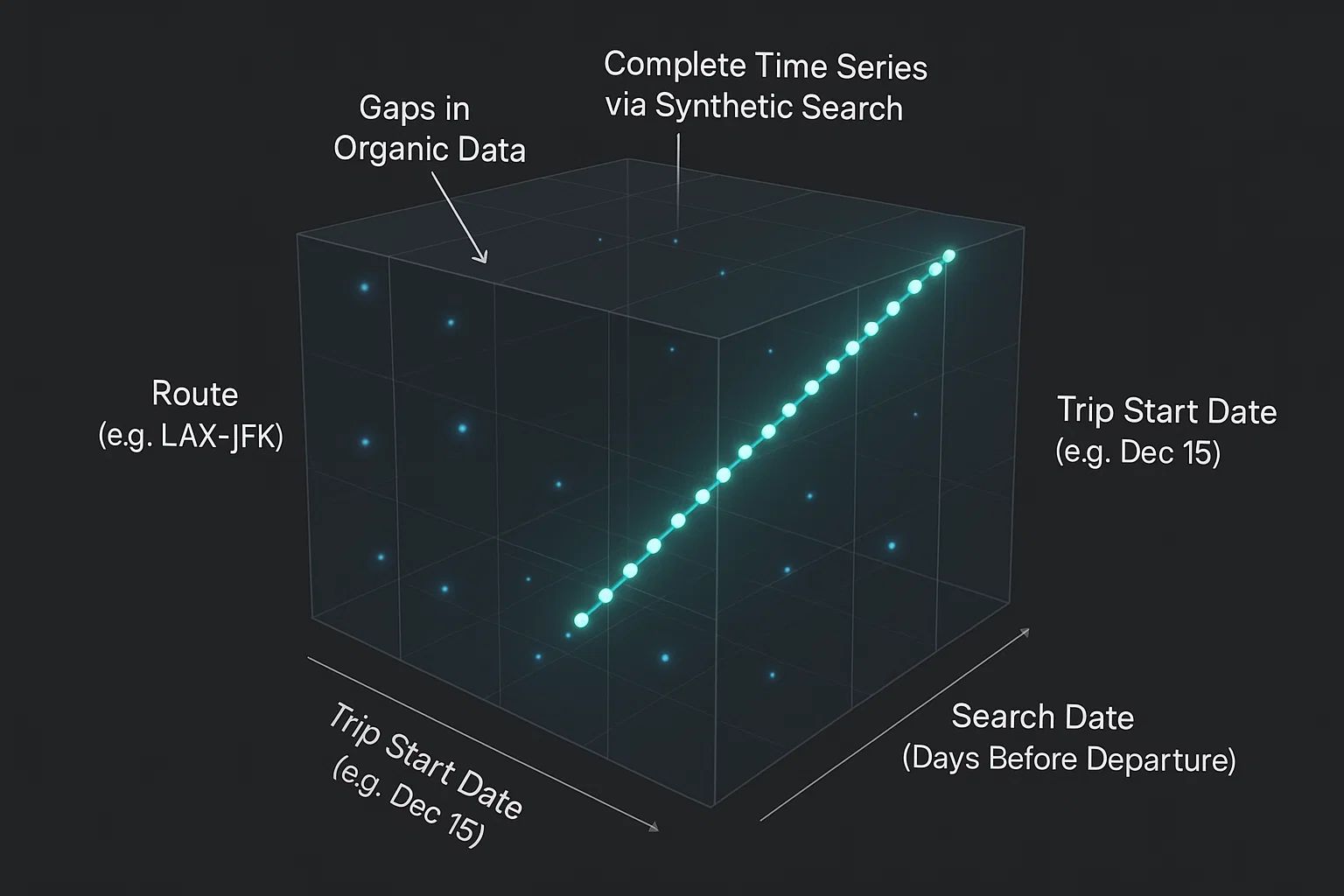
These gaps are poison for time-series models. They break the continuity needed to learn temporal patterns like trends and seasonality. A model might misinterpret a price jump simply because it missed the gradual price changes over the missing days. For a robust forecasting system, this is unacceptable.
The Solution: Manufacturing a Perfect Dataset
The Expedia Group team’s solution was to pivot from passively collecting data to actively generating it. This is the essence of synthetic search data. Instead of waiting for a user to perform a search, an automated system performs the exact searches needed to build a complete dataset.
This system acts like a disciplined, methodical user. Every day, it queries the flight search service for a predefined set of high-value routes. For each of these routes, it systematically searches for a range of future departure dates and trip lengths. The result is a clean, dense, and perfectly consistent dataset where, for the tracked itineraries, there is exactly one price observation per day.
This approach effectively turns a sparse, unpredictable data source into a dense, reliable one, creating the ideal input for a time-series forecasting model.
How It Works: A Look Under the Hood
The architecture for generating synthetic data is a classic example of a simple, effective data engineering pipeline.
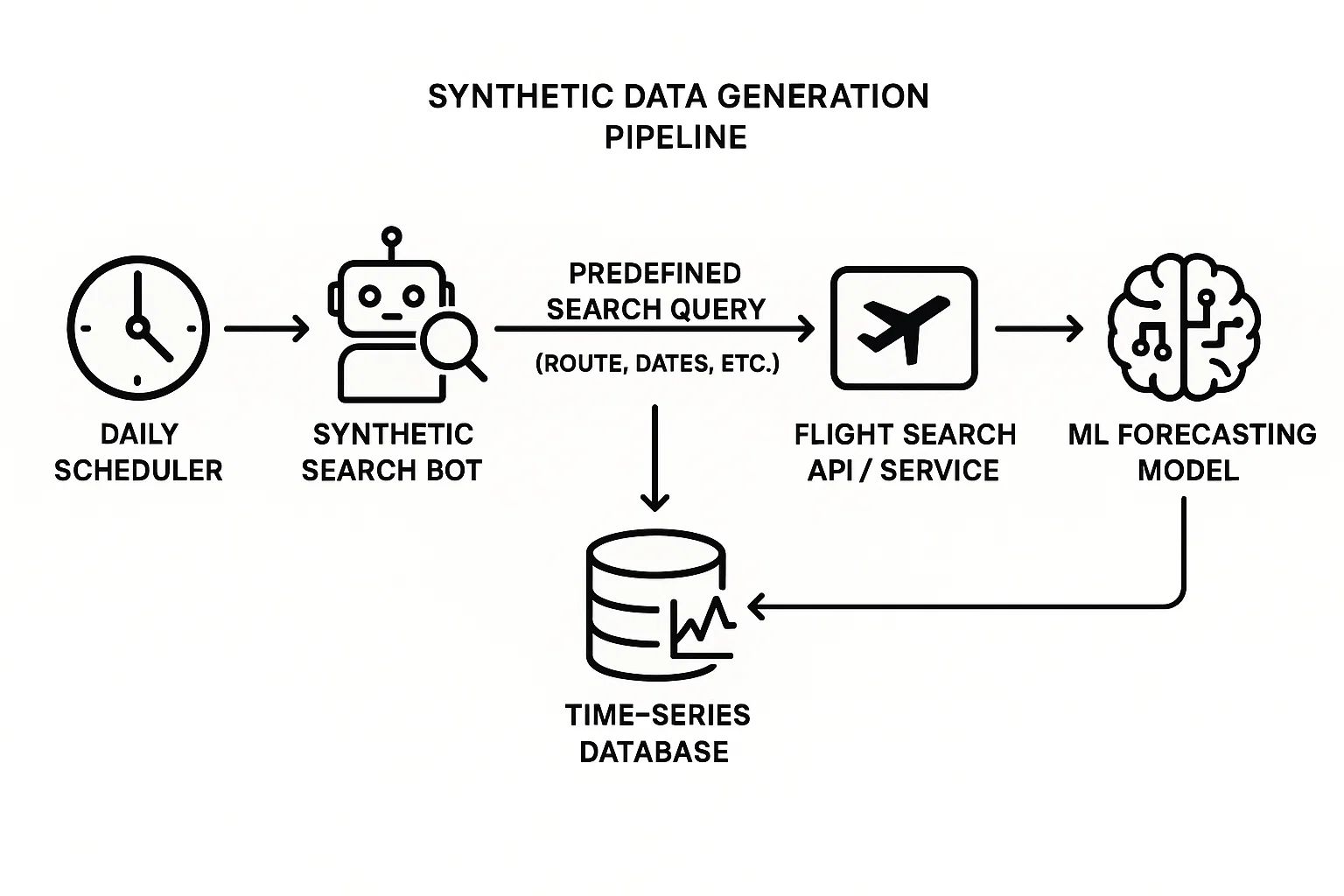
Define the Scope: The process starts with a business decision. Since generating data for every possible route is infeasible (more on that later), the team selects a curated set of the most popular and commercially important routes. This includes defining the "advance purchase window" (e.g., search for all trips starting in the next 180 days) and the trip lengths to cover (e.g., 5-day, 7-day, and 14-day roundtrips).
Automated Execution: A daily scheduled job kicks off the process. This automated process, or "bot," iterates through the predefined list of routes and dates.
Mimicking the User: For each combination, the bot constructs a search query and sends it to the same production flight search service that real travelers use. This is a critical detail: the data generated is not a simulation. It's the real-time price returned by the live system, reflecting actual market conditions, seat availability, and pricing logic.
Ingestion and Storage: The price data returned by the service is captured and stored in a structured time-series database. The key for each record is the full itinerary tuple, and the value is the price for that
search_date.
With this pipeline running daily, the team builds a "golden dataset." For the routes within scope, they have a complete, gap-free price history, perfect for training and evaluating their forecasting models. This high-quality data allows them to build more accurate models, leading directly to a better product for travelers who rely on these price predictions to decide when to book.
Costs and Trade-offs
This solution sounds perfect, but in engineering, there's no free lunch. The team had to carefully weigh the benefits against some significant drawbacks.
System Load and Cost: Every synthetic search is a real query to the live flight search service. At scale, this adds a non-trivial load to the production systems. The infrastructure must serve these automated requests on top of the millions of organic searches from travelers. This has a direct computational cost and requires careful capacity planning to ensure that the synthetic search traffic never degrades the user experience for actual customers.
Limited Scalability: Because of the cost and load, this approach cannot scale to cover all possible flight routes. The team had to make a strategic choice to focus on a subset of routes that covered a significant percentage of searches and bookings. This is a classic Pareto principle application: focus resources on the 20% of routes that drive 80% of the value.
Data Storage Costs: High-frequency, dense data collection leads to large datasets. Storing this data incurs costs that must be factored into the overall budget for the project.
For the initial models, the decision was clear: the value of having a consistent and reliable dataset for a set of high-impact routes far outweighed the operational costs. It provided a solid foundation to launch and validate the first version of the price forecasting feature.
Towards a Generalized Model
The synthetic data approach is brilliant for building highly accurate, specialized models for a fixed set of routes. But the ultimate goal is to provide a forecast for any search a traveler performs.
This is where the vision shifts from specialized models to a single, generalized forecasting model. Such a model wouldn't rely on a dense time series for every single route. Instead, it would learn the fundamental patterns of price dynamics by looking at features of the route itself (e.g., airport popularity, carrier competition, distance) combined with temporal features (e.g., seasonality, day of the week, holidays).
This is a much harder machine learning problem, likely requiring more sophisticated deep learning architectures. So, does this make the synthetic dataset obsolete?
Quite the opposite. The synthetic data becomes an invaluable asset for building this generalized model in two ways:
High-Quality Training Data: It serves as a high-quality, representative sample of price dynamics that can be used to train the generalized model.
A "Ground Truth" for Validation: More importantly, the synthetic dataset acts as a "golden" validation and test set. When you develop a new generalized model, you can test its performance on the routes where you have perfect, complete data. If the model can accurately predict prices for these well-understood routes, it gives you confidence that it has learned meaningful patterns that can be generalized to routes with sparser data.
Key Takeaways
The journey of Expedia's flight price forecasting team offers powerful lessons for any data professional building models on real-world data.
Acknowledge Data Sparsity: Don't assume "big data" means "dense data." Understand the true dimensionality of your problem and proactively check for gaps that could harm your model.
Generate Data Strategically: When faced with sparse data for high-value problems, consider synthetic data generation. It's a powerful tool for creating clean, reliable datasets where they matter most.
Balance Perfection and Pragmatism: Every engineering solution involves trade-offs. The synthetic search approach is a masterclass in balancing the need for perfect data with the real-world constraints of cost, system load, and scalability.
Build Foundational Assets: A high-quality dataset, even if limited in scope, is a long-term asset. It can bootstrap initial models and later serve as a critical benchmark for more advanced, generalized systems.
Ultimately, the best models are built not just on clever algorithms, but on a deep understanding and curation of the data that fuels them. By choosing to manufacture their own data, the Expedia Group team didn't just solve a problem—they built a foundation for a more intelligent and reliable future of travel.