- My Data Dojo
- Posts
- How Apple Mastered On-Device Image Segmentation
How Apple Mastered On-Device Image Segmentation
Fast Class-Agnostic Salient Object Segmentation
Sachin Nowal
August 10, 2025
If you've used an iPhone in the last couple of years, you've likely interacted with some seriously impressive AI without even realizing it. Ever lifted your dog out of a photo to create a perfect sticker? Or marveled at how Portrait Mode flawlessly separates you from a busy background? These features feel like magic, but they're the product of intense engineering and cutting-edge machine learning, running entirely on your device.

The core technology is image segmentation—the task of classifying every single pixel in an image. But Apple's implementation tackles two distinct, challenging flavors of this problem:
Class-Agnostic Salient Object Segmentation: Finding the single most "interesting" or "salient" object in an image, no matter what it is—a person, a plant, a car, or a coffee mug. This powers the "Lift Subject from Background" feature.
Panoptic Segmentation: Going a step further to identify and delineate every element in a scene, distinguishing between "stuff" (like the sky, grass) and "things" (like person 1, person 2). This is the engine behind advanced camera features like Portrait Mode and Photographic Styles.
Doing either of these in the cloud is one thing. Doing them with near-zero latency, on a device with limited power and memory, is a whole different ballgame. It demands a holistic approach where the model architecture, data strategy, and hardware are designed to work in perfect harmony.
Let's dive into the technical details and see how Apple's engineers pulled this off.
Before we begin, this blog present by mydatadojo, is a space for the data science community to explore conceptual insights, real-world case studies, and simplified explanations of core and emerging topics.
Click the link below to learn more and dive into the dojo.

The "Instant Sticker" Problem
The goal here is simple from a user's perspective: touch and hold on a subject, and it should lift out instantly. To the ML engineer, this translates into a tough set of constraints: extremely low latency, high accuracy, and the ability to work on any object, not just a predefined list of classes like "person" or "cat."
The Architecture: Built for Speed
To meet the sub-10 millisecond latency target on an iPhone 14, the team built a lightweight and efficient model. It's a classic encoder-decoder structure, but the devil is in the details.

Encoder: An
EfficientNetV2backbone processes a 512x512 resized input image. This model is well-known for providing a great balance of accuracy and computational efficiency.Decoder: A convolutional decoder upsamples the features extracted by the encoder to produce a segmentation mask.
Dynamic Reweighting: A small branch takes the final features from the encoder and predicts an affine channel-wise reweighting for the decoder's output. This is a form of dynamic convolution; instead of having fixed filters, the network learns to create the best filter on the fly for the specific image, which sharpens the results.
Confidence Gating: This is a simple but brilliant product-focused addition. The segmentation task is inherently ill-posed—what's "salient" can be ambiguous. To avoid showing the user a weird or unexpected result, a separate, tiny branch predicts a single scalar value: the model's confidence that there's a clear foreground subject. If the confidence is too low, the result isn't shown. Think of it as a quality-control gatekeeper.
Detail-Preserving Upsampling: The network outputs a 512x512 mask, but your photo might be 12MP. Simply resizing this low-resolution mask would result in blurry edges. To preserve fine details like hair and fur, the system uses a Guided Filter. This is a classic computer vision technique that uses the original high-resolution image as a "guide" to intelligently upsample the mask, ensuring the final cutout has sharp, high-fidelity edges.
The entire network is optimized to run on the Apple Neural Engine (ANE), a dedicated coprocessor for ML tasks. On older devices without a powerful ANE, it falls back to the GPU, leveraging highly optimized Metal Performance Shaders.
The Camera Problem: Understanding the Whole Scene with HyperDETR
For features like Portrait Mode or Photographic Styles, isolating one object isn't enough. The camera needs a complete, pixel-perfect map of the scene. It needs to know: "this is sky," "this is skin," "this is hair," "this is person 1," and "this is person 2." This is panoptic segmentation.
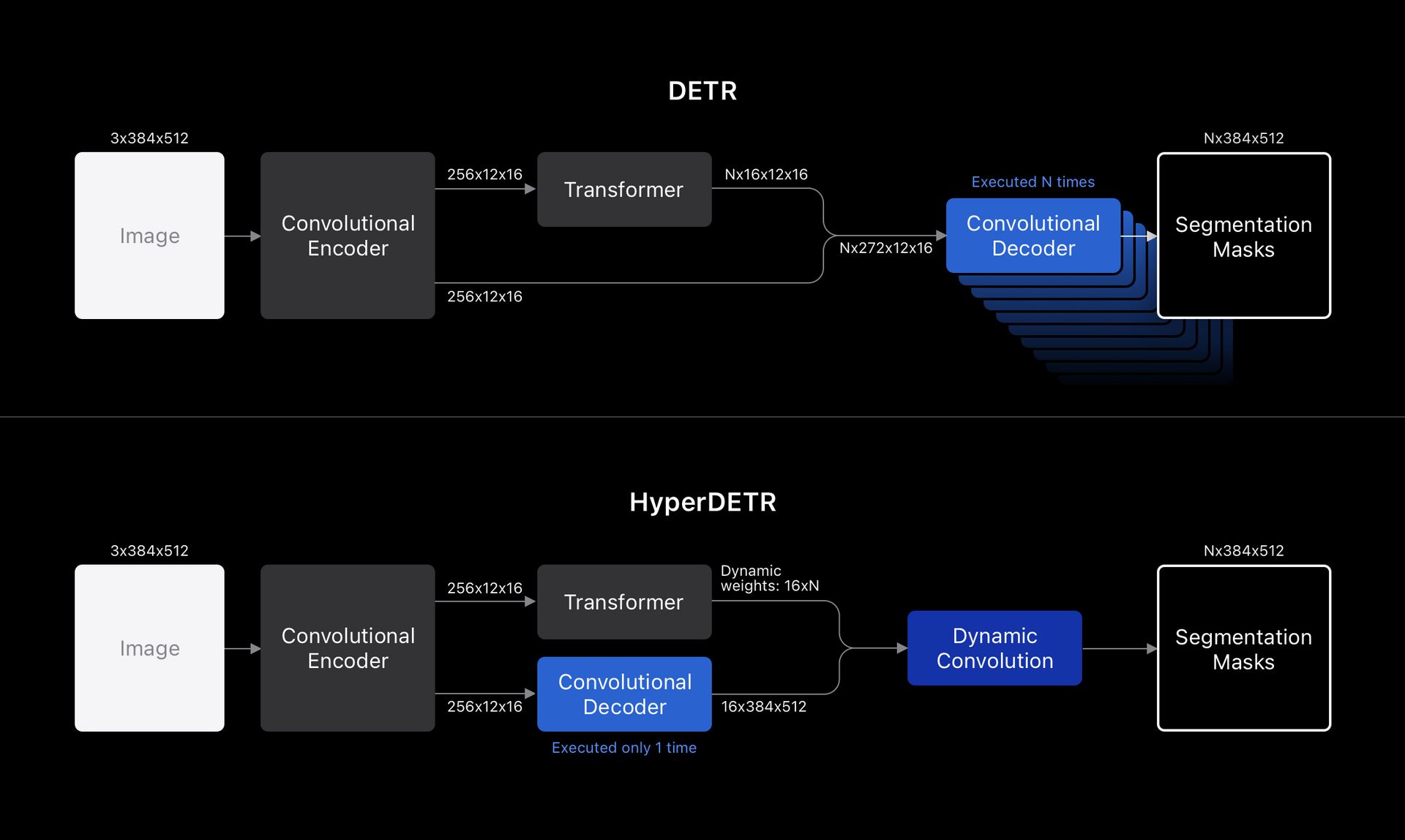
The standard architecture for this kind of task in modern ML is the DEtection TRansformer, or DETR. DETR is elegant because it gets rid of complex post-processing steps like non-maximum suppression (NMS). However, the original DETR is a computational beast, especially for generating high-resolution masks. It becomes the dominant bottleneck, making it completely unsuitable for on-device, real-time use.
The problem lies in how DETR generates masks. For every potential object (or "query"), it runs the entire mask decoder. If you have 100 queries, you run the decoder 100 times. This scales terribly.
The Breakthrough: HyperDETR
To solve this, Apple's engineers developed HyperDETR, a simple but profound architectural change inspired by HyperNetworks. The core idea is to decouple the "what" from the "where."
The convolutional decoder is responsible for the "where." It runs only once per image, creating a rich set of high-resolution feature maps—a shared canvas of potential mask components.
The Transformer is responsible for the "what." It processes the image and outputs a tiny set of parameters for each detected object. Crucially, these parameters are not a mask. They are the weights for a final
1x1dynamic convolution layer.
This final layer acts as an assembler. It takes the shared feature maps from the convolutional decoder and, using the weights provided by the Transformer, linearly combines them to produce the final mask for each specific object.
The benefits are massive:
Efficiency: The expensive convolutional decoder runs only once, not N times. Its complexity is now independent of the number of objects you want to detect.
Modularity: Scene-level categories like "sky" can be handled purely by the convolutional path, allowing the system to skip the Transformer entirely when only semantic segmentation is needed.
This factorization is the key that makes high-resolution panoptic segmentation tractable on a smartphone.
The Engineering Grind: From Model to Magic
A clever architecture is just the starting point. Getting these models to "shipping quality" involves a relentless process of optimization and practical engineering.
Compression is Non-Negotiable
A pre-trained HyperDETR model might be 84MB. That's too big. The team applied several compression techniques:
Quantization: All model weights were converted to 8-bit integers, immediately cutting the size by 75% to around 21MB with minimal loss in accuracy.
Architectural Pruning: They found that the last 4 layers of the 6-layer Transformer decoder could be removed with negligible impact on quality. This is because each layer was supervised during training, so the earlier layers were already quite powerful. This trick shaved off another ~4MB, bringing the final model to a lean 17MB.
Data and Evaluation Beyond the Benchmarks
You can't create a class-agnostic model without class-agnostic data. The team used a combination of real-world annotated images and synthetically generated data. This included composing real and synthetic foregrounds onto random backgrounds on-the-fly during training, creating an almost infinite stream of diverse examples.
Most importantly, they recognized that academic metrics like Intersection-over-Union (IoU) don't tell the whole story. A model can have a high IoU but produce results that feel wrong to a user. To capture these nuances, they relied heavily on crowd evaluation, where human annotators rated the quality of the model's output. This human-in-the-loop feedback was critical for focusing on improvements that directly impacted the user experience.
Key Takeaways
Deconstructing Apple's on-device segmentation features reveals a masterclass in building production-ready ML systems. The lessons here are valuable for any data scientist or engineer working on deploying models in resource-constrained environments.
It's a Systems Problem: Success isn't just about a novel architecture. It's about the deep integration of the model, data pipelines, compression techniques, and specialized hardware like the ANE.
Solve the Bottleneck: HyperDETR is a perfect example of identifying the single biggest performance bottleneck in an architecture (the batched decoder) and redesigning the data flow to eliminate it.
Design for the Product: Features like the confidence-gating branch aren't for improving benchmark scores; they're for preventing bad user experiences. This product-centric mindset is crucial.
Measure What Matters: Standard metrics are a starting point, but for user-facing features, nothing beats direct human feedback. Measuring perceived quality is key to building a product people love.
The next time you lift a subject from a photo, take a moment to appreciate the incredible dance of engineering happening under the glass—a powerful, efficient, and private AI working to deliver a little bit of magic, just for you.