- My Data Dojo
- Posts
- Direct Preference Optimization
Direct Preference Optimization
Alignment shouldn’t be a luxury only top labs can afford.
Sachin Nowal
August 02, 2025


Modern large language models represent one of the most remarkable achievements in artificial intelligence. Yet for all their impressive capabilities—from writing code to analyzing complex documents—these models often generate responses that don't quite align with what humans actually want. They might be technically correct but unhelpful, verbose when brevity is needed, or occasionally produce harmful content despite extensive training.
This alignment challenge has traditionally been addressed through Reinforcement Learning from Human Feedback (RLHF), a complex multi-stage process that, while effective, resembles trying to tune a race car while it's speeding around the track. The process involves training separate reward models, dealing with unstable reinforcement learning algorithms, and managing multiple moving parts that can break in subtle ways.
Enter Direct Preference Optimization (DPO)—an elegant solution that cuts through this complexity like a sharp knife through butter. Instead of the intricate dance of RLHF, DPO offers a direct path from human preferences to aligned models, transforming what was once a complex engineering challenge into a straightforward optimization problem.
The Problem with Traditional Alignment
To understand why DPO represents such a breakthrough, we need to first grasp the challenges inherent in traditional RLHF approaches. The standard RLHF pipeline involves three distinct stages, each with its own computational and methodological complexities.
The process begins with supervised fine-tuning (SFT), where we teach a pre-trained model to follow instructions using high-quality example conversations. This step transforms a base language model into something that can engage in dialogue and follow basic instructions. While conceptually straightforward, SFT requires carefully curated datasets and significant computational resources.
Next comes the reward modeling stage, where we train a separate neural network to predict human preferences. This reward model learns to score different responses to the same prompt, essentially trying to capture human judgment in mathematical form. The challenge here is that human preferences are nuanced, context-dependent, and often inconsistent—qualities that don't translate easily into a single scalar reward.
Finally, we reach the reinforcement learning stage, typically using Proximal Policy Optimization (PPO). This is where the complexity really explodes. PPO requires maintaining four different copies of the language model in memory simultaneously: the current policy, a reference policy, the reward model, and a value function. The training process involves sampling responses from the model, scoring them with the reward model, and then updating the policy using complex RL algorithms that are notoriously difficult to tune and prone to instability.
The computational overhead is staggering. Training with PPO-based RLHF typically requires massive GPU clusters and can take weeks to complete. Even worse, the process is fragile—small changes in hyperparameters can cause training to collapse, and the online nature of RL means you're constantly generating new data during training, making the process difficult to reproduce and debug.
Simplicity Through Mathematical Elegance
DPO represents a fundamental rethinking of the alignment problem. Instead of trying to learn a reward model and then optimize against it with RL, DPO recognizes that the preference data itself contains all the information we need to directly optimize the policy.
The key insight is surprisingly simple:
if we know that humans prefer response A over response B for a given prompt, we can directly train our model to increase the probability of generating responses like A while decreasing the probability of responses like B. No separate reward model needed. No complex RL algorithms required. Just straightforward gradient descent on a cleverly designed loss function.
Mathematical Foundation
The elegance of DPO lies in its mathematical derivation, which starts from the same theoretical foundation as RLHF but arrives at a much simpler solution. The process begins with the standard RLHF objective: maximize expected reward while staying close to a reference model to prevent the policy from drifting too far from reasonable behavior.
Rather than solve this optimization problem with RL, DPO derives the closed-form solution directly. Through a series of mathematical transformations, the authors of the original DPO paper show that the optimal policy can be expressed in terms of the reference model and an implicit reward function derived from the policy itself.
This leads to the DPO loss function, which is beautifully simple:
def dpo_loss(policy_chosen_logps, policy_rejected_logps,
reference_chosen_logps, reference_rejected_logps,
beta=0.1):
"""
Direct Preference Optimization loss function
"""
# Calculate log ratios for chosen and rejected responses
policy_logratios = policy_chosen_logps - policy_rejected_logps
reference_logratios =
reference_chosen_logps - reference_rejected_logps
# Implicit reward difference
logits = policy_logratios - reference_logratios
# DPO loss using Bradley-Terry model
losses = -F.logsigmoid(beta * logits)
return losses.mean()This loss function accomplishes several things simultaneously. It increases the likelihood of chosen responses, decreases the likelihood of rejected responses, and maintains a KL divergence penalty to prevent the model from drifting too far from the reference policy—all without requiring an explicit reward model or RL training.
The Bradley-Terry Foundation
At the heart of DPO lies the Bradley-Terry model, a statistical framework originally developed for modeling pairwise comparisons in sports and games. The Bradley-Terry model provides a principled way to convert pairwise preferences into probability distributions.
In the context of language models, the Bradley-Terry model tells us that the probability of preferring response A over response B should be proportional to the exponential difference in their implicit rewards. DPO leverages this relationship by parameterizing the reward function implicitly through the policy itself, eliminating the need for a separate reward model.
This connection to the Bradley-Terry model isn't just mathematical convenience—it provides theoretical guarantees about the optimality of the learned policy. When DPO converges, the resulting model provably solves the same optimization problem as RLHF, but through a much more direct path.
From Theory to Production
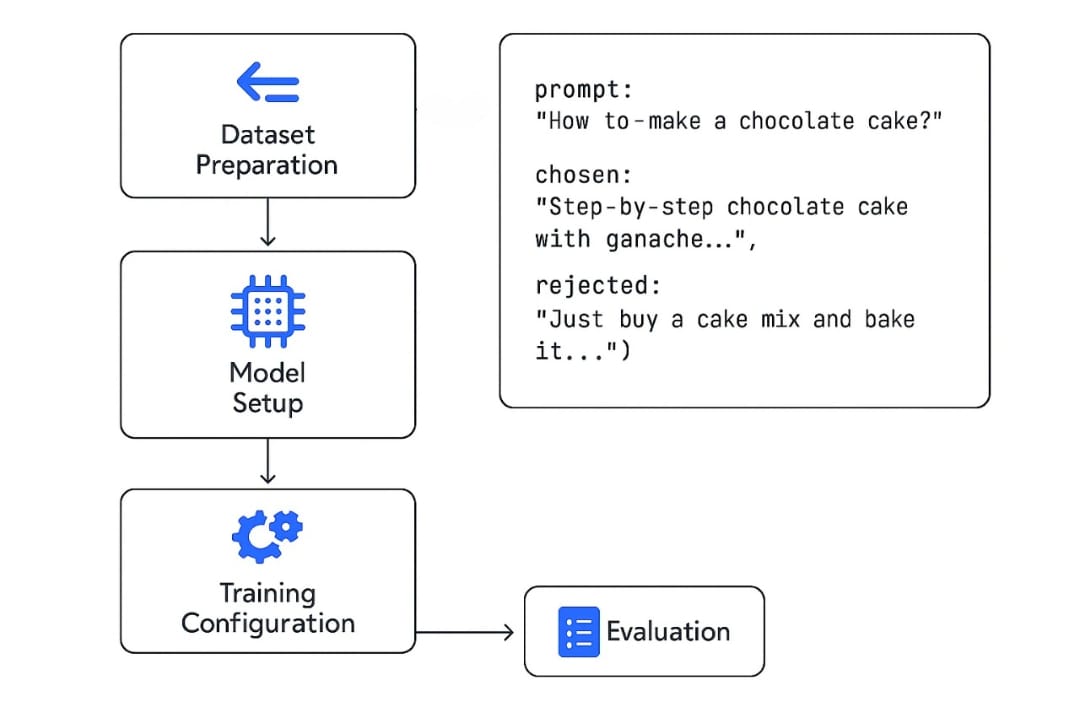
For data scientists and ML engineers looking to implement DPO in practice, the process is straightforward compared to RLHF. The typical DPO workflow consists of four main steps:
dataset preparation
model setup
training configuration
evaluation
1. Dataset Preparation
DPO requires preference data in a specific format: each example must contain a prompt, a chosen response, and a rejected response. The quality of this data is crucial—poor preference data will lead to poor alignment regardless of the optimization method used.
Imagine you're building a cooking assistant. You give it a prompt:
👉 “How to make a chocolate cake?”
The model generates two answers:
🍰 Recipe A (Chosen)
🧁 Recipe B (Rejected)
The data format looks like:
{
"prompt": "How to make a chocolate cake?",
"chosen": "Step-by-step chocolate cake with ganache...",
"rejected": "Just buy a cake mix and bake it..."
}2. Model Setup
You start with a base model (e.g., LLaMA, Mistral, GPT, etc.).
The goal is to adjust its responses so it more often gives answers like the "chosen" ones from your dataset.
3. Training Configuration
One of DPO's major advantages is its minimal hyperparameter tuning requirements. The key parameter to tune is beta (β), of which typical values range from 0.1 to 0.5. It controls how much the new model is allowed to drift away from the original base model.
High β = “Stick close to what you were already doing.”
Low β = “Feel free to explore new styles based on preferences.”
Unlike RLHF’s PPO (which has 5+ tricky knobs), DPO just needs this one main dial.
4. Training
Instead of giving the model a score or reward, we ask:
“Which of these answers should the model prefer — and how confident is it?”
DPO Loss Function:
loss = -log σ [ β·(log pₜ(chosen) − log pₜ(rejected))
− β·(log p_ref(chosen) − log p_ref(rejected)) ]All it's doing is:
Comparing how much the current model and the original model prefer A over B.
Pushing the current model to favor A more strongly, without deviating too far from the original.
You can code this in <20 lines with PyTorch. No reinforcement learning. No value networks. No reward models.
A Complete Training Example
Here's a practical implementation using HuggingFace's TRL library:
from trl import DPOTrainer
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("llama-7b")
tokenizer = AutoTokenizer.from_pretrained("llama-7b")
# Load preference data
dataset = [
{"prompt": "How to make a chocolate cake?",
"chosen": "Start with flour, sugar, cocoa powder...",
"rejected": "Just buy a ready-made mix..."}
]
# Define trainer
trainer = DPOTrainer(
model=model,
tokenizer=tokenizer,
beta=0.1,
train_dataset=dataset
)
# Train!
trainer.train()This example demonstrates the entire DPO workflow, from loading a pre-trained model to training and evaluation. The simplicity compared to RLHF is striking—no reward model training, no complex RL setup, just straightforward supervised learning on preference data.
Why Is DPO So Easy?
Feature | RLHF (PPO) | DPO |
|---|---|---|
Needs reward model? | ✅ Yes | ❌ No |
Complex tuning? | ✅ Yes (many knobs) | ❌ No (mostly β) |
Easy to implement? | ❌ Hard | ✅ Very easy |
Great for small teams? | ❌ Needs RL expertise | ✅ Yes! |
A Mini-Case Study: Aligning a Legal-Advice Bot
Problem: A law firm wants an LLM assistant that drafts simple contracts. Unaligned, the model occasionally uses outdated clauses or overly verbose legalese.
Data: They collect 5,000 examples where junior attorneys compare two contract drafts and select the clearer, more accurate one.
Solution with DPO:
SFT baseline: Supervised fine-tune on a small corpus of high-quality contracts.
Collect references: Use that SFT model to generate paired contract drafts per prompt.
Human preferences: Have lawyers pick the better draft.
DPO alignment: Run the DPO pipeline (β=0.2, 3 epochs, batch size=8).
Outcome: The final model consistently produces concise contracts, matching senior attorney preferences over 85% of the time in blind tests—and achieved this in under 100 GPU-hours, versus an estimated 500+ GPU-hours for a comparable PPO run.
Technical Deep Dive: Understanding the Gradient Flow
For ML engineers interested in the technical details, understanding how DPO's gradients flow during training provides insight into why the method works so well. The DPO loss gradient has three key components that work together to achieve alignment.
The weighting term assigns higher importance to examples where the implicit reward estimate is incorrect. This means the model focuses its learning on cases where it currently makes poor preference judgments, naturally prioritizing the most informative examples.
The likelihood adjustment terms increase probability mass on chosen responses while decreasing it on rejected responses. This is similar to standard supervised learning, but with the crucial addition of the implicit reward weighting that ensures the updates are well-calibrated.
The KL regularization prevents the model from changing too dramatically from the reference policy. This is built into the loss function automatically, unlike RLHF where the KL penalty must be carefully tuned as a separate hyperparameter.
This elegant combination means that DPO naturally addresses many of the stability issues that plague RLHF training. The model can't easily exploit the reward function because the reward is implicit and tied to the policy itself. This eliminates the reward hacking that sometimes occurs in RLHF.
Limitations and Considerations
Despite its many advantages, DPO is not a silver bullet for all alignment challenges. Understanding its limitations is crucial for practitioners considering when and how to apply the method.
A. Generalization Challenges
Recent research has highlighted that DPO's implicit reward model may not generalize as well as explicit reward models when faced with distribution shifts. While DPO performs comparably to RLHF on in-distribution data, it can show larger performance drops when evaluated on data that differs from the training distribution.
This limitation is particularly relevant for production systems that may encounter edge cases or evolving user behavior. Organizations using DPO should implement robust monitoring and potentially consider hybrid approaches that combine DPO with explicit reward models for critical applications.
B. Data Quality Dependencies
DPO's performance is heavily dependent on the quality of the preference data. Poor quality preferences—whether due to inconsistent human judgment, biased annotators, or inadequate annotation instructions—will directly impact model alignment. This puts a premium on thoughtful data collection and quality assurance processes.
Unlike RLHF, where poor reward model performance might be visible during training, DPO's implicit reward means that data quality issues may only become apparent during evaluation. This makes careful dataset curation and evaluation even more important.
C. Computational Trade-offs
While DPO is more computationally efficient than RLHF during training, it still requires maintaining a reference model in memory during training. For very large models, this can present memory constraints that need to be carefully managed through techniques like gradient checkpointing or model sharding.
Performance Benchmarks and Evaluation
Evaluating the effectiveness of DPO requires careful consideration of multiple dimensions: alignment quality, computational efficiency, and robustness. Across various benchmarks, DPO has demonstrated competitive or superior performance compared to RLHF while offering significant practical advantages.
On conversational benchmarks like MT-Bench, DPO-trained models consistently match or exceed the performance of RLHF-trained models. In code generation tasks, DPO has shown particular strength, likely due to the clearer preference signals available in programming tasks where correctness can be more objectively assessed.
The computational advantages are striking: DPO typically requires 2-3x less GPU time than comparable RLHF training while using significantly less memory due to the elimination of the reward model and value function. This efficiency gain has made alignment training accessible to smaller organizations and research groups.
Implementation Best Practices
Based on real-world deployments and research findings, several best practices have emerged for successful DPO implementation:
Start with high-quality SFT models: DPO works best when applied to models that already demonstrate basic instruction-following capabilities. Attempting to use DPO on base models without prior supervised fine-tuning typically leads to poor results.
Invest in preference data quality: The old adage "garbage in, garbage out" applies strongly to DPO. Invest time in creating clear annotation guidelines, training annotators, and implementing quality control measures for preference data collection.
Monitor for distribution shifts: Implement robust evaluation pipelines that test model performance on data that differs from the training distribution. This helps identify potential generalization issues early.
Tune beta conservatively: Start with β = 0.1 and increase cautiously if needed. Higher beta values can lead to more aggressive optimization but may also increase instability.
The Future of DPO and Alignment Research
DPO represents more than just a more efficient alternative to RLHF—it's a paradigm shift in how we think about alignment. By demonstrating that complex RL machinery isn't necessary for preference learning, DPO has opened new research directions and made alignment techniques more accessible.
Current research is exploring extensions to multi-turn conversations, integration with constitutional AI approaches, and applications to reasoning-heavy tasks. The mathematical framework of DPO has also inspired related techniques like Identity Preference Optimization (IPO) and Kahneman-Tversky Optimization (KTO), each addressing different aspects of the preference learning problem.
Looking ahead, we can expect to see DPO integrated into the standard toolkit of any organization working with language models. Its combination of theoretical soundness, practical efficiency, and implementation simplicity makes it an ideal technique for the production deployment of aligned AI systems.
For the data science and ML engineering community, DPO represents an opportunity to deploy sophisticated alignment techniques without the complexity traditionally associated with RL-based approaches. As the field continues to evolve, DPO's elegant simplicity ensures it will remain a cornerstone of practical AI alignment for years to come.
The journey from complex RLHF pipelines to the elegant simplicity of DPO exemplifies how the best scientific breakthroughs often involve not adding complexity, but removing it. By recognizing that the solution to alignment was hiding in plain sight within the mathematics of preference learning itself, DPO has transformed a complex engineering challenge into an accessible and reliable technique that any ML practitioner can implement and deploy.